What is Machine Learning Ops
- Vishwanath Akuthota
- Jul 27, 2022
- 7 min read
Updated: Oct 12, 2022
In this article, we’ll focus on dissecting the three main aspects of model deployment.
These are:
experiment tracking
machine learning model management
MLOps (machine learning operations)
What is MLOps
Deploying machine learning models involves a set of tools, principles, and practices. It’s similar to DevOps, only there the goal is to optimize how software development projects are launched. In the machine learning world, these tools and practices are referred to as MLOps. Generally, MLOps is the application of DevOps principles in machine learning.

MLOps Source: Google
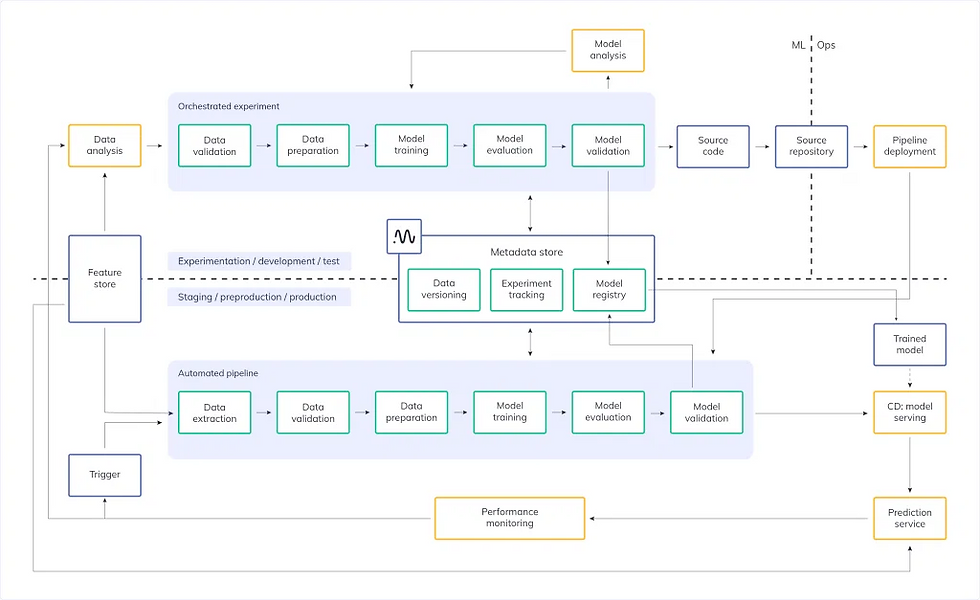
Modified from ML pipeline automation by Google Cloud
Feature store
This is a central repository that provides access to features for training and serving. It is important because it:
enables the re-use of features instead of creating new ones,
prevents the use of similar features with different definitions,
lets you serve feature values that are up-to-date,
ensures that features used for training are also used during model serving.
Data versioning
Machine learning models can always be re-trained when new data is available. They can also be re-trained when there’s a new training approach.
It’s possible that re-training the model on new data could lead to poor performance. In such a case, versioning lets you revert to the previous model, and you will know which version of the data led to the dismal performance. Versioning is also crucial for regulatory compliance, as well as data auditing.
ML metadata store
Here, all information about the model execution is recorded in order to help with reproducibility and comparison. This can also help in detecting anomalies and debugging. Some of the information that is recorded includes:
parameters used to run the pipeline,
the start and end time of the process,
links to various artifacts used in the pipeline,
pointer to the last trained model in the event that you need to revert to it,
model evaluation metrics for the training and testing set to enable comparison with previous models,
who created the model,
when the model was created,
feature transformations that were applied,
dataset used to create the model.
Storing model metadata gives you the power of model searchability. For example, you can search for models based on the features, model types, and training dates. This searchability enables the management, analysis, experimentation, and tracking of many models.
Model metadata lets you compare different models and decide which one to put in production. It’s also vital in determining a team’s progress so as to identify areas that might require more effort. Tracking all metadata manually can quickly turn into a nightmare. Fortunately, you can use ML tools to automatically extract metadata from your ML pipeline, and log it.
What is ML model management
These practices and methodologies can make you quicker at experimenting and developing machine learning models. In this section, let’s look at how this works.
Model serving
The active model version can be served to target applications via a REST API. Other MLOps systems will allow you to download the model on the target device. The advantage of this is that the model will be automatically updated on the target device whenever a new version is available. So, you don’t need to ship a new version of your application whenever your model changes.
You can also serve different versions of your model, monitor them and settle on the best performer.
Model versioning
The ability to go back in time to a certain state of a model is crucial. For this to be possible, you need to be able to version various aspects of model development. For example:
notebooks,
datasets used,
hyper-parameter sets,
code,
artifacts.
To revert to previous models, you need to be able to uniquely identify each model instance. You can’t change the model while it’s in production. Each model should be immutable.
Altering the model while it’s in production could lead to unexpected behaviour, so it’s rarely done. Version the models is more common, because it gives you the power to switch between various model versions on demand.
You might need a new model version because of:
model architecture change, e.g. change from a neural net to a Scikit-learn linear regression,
hyper-parameter change,
feature addition/removal,
re-train of the model.
Model monitoring
Once a machine learning model is in use, it has to be monitored. There are two main items that need to be monitored: model drift and production skew.
Model drift is a scenario where the statistical properties of the item being predicted change in ways that can’t be predicted. So, if the statistical properties of the training data and prediction data become unpredictable, the performance of the model will degrade. If you’re monitoring, you will be able to capture this problem and swiftly solve it.
Production skew happens when the performance of the offline model is significantly different from the performance of the served model. This could result from:
bugs in training,
bugs in the serving implementation,
inconsistencies between the training data and the one being passed to the model.
Detecting model drift and production skew will ensure that your model performs as expected in a production environment.
Model retraining
It’s important to always re-train the model when there’s a need to do so, as informed by model evaluation. The model can also be retrained when new data is available.
As mentioned in the last part, production models are prone to model drift and production skew. When you notice this in your application, the model can be retrained with new data. Your production system should therefore automatically detect model drift and send alerts that trigger model retraining.
That said, some models may not improve and should be discarded instead of retraining, to save computational resources that would have gone into a model that can’t improve.
Again, your system should automatically be able to detect such scenarios, deprecate the model, and train a new model on new data. Your deprecated models should remain on your server until all systems using those models are migrated to new ones.
When re-training models, a rule system should be used. For example, a new model should only be used when its mean absolute error is below that of the previous one. In that case, the new model should be fetched automatically and deployed. The rules can also be set so that they check for a certain threshold in error and/or accuracy.
Before rules are implemented in a production environment, they need review. You can do this through peer reviews in a Git-based system. This is crucial because productionizing the wrong rules could lead to system outages.
What is experiment tracking
Developing performant machine learning often involves iterating over several experiments. These experiments need to be tracked for comparability and reproducibility.
In order to achieve that, one needs to log the experiment metadata. For example code versions, data versions, and so on. As we previously mentioned, model management is what happens when a model moves to production. However, not all models graduate to production, and not all of them should.
In order to obtain the best model that will be moved to production, tracking all experiments is critical. It would be very unlucky to be unable to reproduce an experiment with the best performance. With that in mind, let’s look at various parts of experiment tracking.

Source:neptune
Model training
At this stage, you develop a training pipeline. The pipeline is responsible for:
ingesting data,
engineering new features,
monitoring the training process.
During this stage the features are validated to be the same as in the feature store. Using different features can lead to problems when the pipeline is used on real-world data. The pipeline also ensures that data is passed to it with the right quality and format.
Training can be done over several experiments. Each of the experiments is logged in detail by your experimentation tool. Once the process is complete, you can reproduce the experiment that resulted in the best performance. Furthermore, by logging the models themselves, you can immediately pick the model that resulted in the best performance.
Model evaluation
At this stage the model is tested with data that it has never seen before, in readiness for deployment. The test data features should be similar to the ones used in training. Otherwise evaluation will fail. If the performance is dismal then retraining the model can be done after adjusting the features and/or the data.
Model registry
When using an experimentation tool, you can save your best models to a model registry. Once you obtain the best model, this makes it ready for serving. It depends on the experimentation tool you’re using, but this sort of functionality should be provided out of the box.
It’s also important to note that the model registry can be used in the retraining phase in model management. Once you have a new model, you’ll need to update the model registry.
The model registry is important because it contains model metadata. This metadata is important for several reasons:
managing the models,
complying with regulatory frameworks in your region,
knowing if the model is running in production and at which end point.
We’ve covered a lot of ground so far. Let’s take a moment and briefly sum it up by comparing the techniques.
MLOps vs experiment tracking
To develop any machine learning model, you need to try a lot of features, parameters and datasets. This can result in a lot of models.
Although most models will be discarded, it’s important to track every single experiment. It would be very unfortunate not to be able to reproduce a model that performed well because you have no information about why it performed well. This process – running several experiments and comparing them – is what experiment tracking is all about. Once you have an optimal model that you would like to move to production, then MLOps steps in.
MLOps vs ML model management
MLOPs is about successful deployment and serving of your machine learning models. Simply speaking, all the MLOps steps ensure that your model is always available. When you are certain that the model itself will always be available, you then need to manage the model itself.
ML model management vs experiment tracking
Your goal in model management is to keep track of the various models in your registry and serve them. The models need to be monitored so that in the event of a performance drop, the necessary measures can be taken.
Now, the way the model gets in the model registry in the first place is through the experimentation stage. This is where you run experiments on various models, and send the best performing one to the model registry. Once it’s there, you can always trigger retraining and remodelling when the conditions dictate so. In that light, experiment tracking and model management are two processes that depend on each other.
Comments